Cybersecurity researchers at LayerX have uncovered a critical vulnerability in OpenAI’s ChatGPT Atlas browser that enables threat actors to inject malicious instructions into ChatGPT’s memory system through Cross-Site Request Forgery attacks.
The flaw, disclosed responsibly to OpenAI on October 27, 2025, represents the first publicly documented security issue affecting the company’s new agentic browser and poses significant risks to users who rely on AI-assisted coding and system management.
CSRF Exploitation Enables Memory Poisoning Attacks
The vulnerability exploits a fundamental weakness in how ChatGPT Atlas handles authenticated sessions and cross-site requests.
Attackers can leverage CSRF techniques to piggyback on a victim’s existing ChatGPT authentication credentials, allowing unauthorized access to inject hidden instructions directly into the platform’s memory feature.
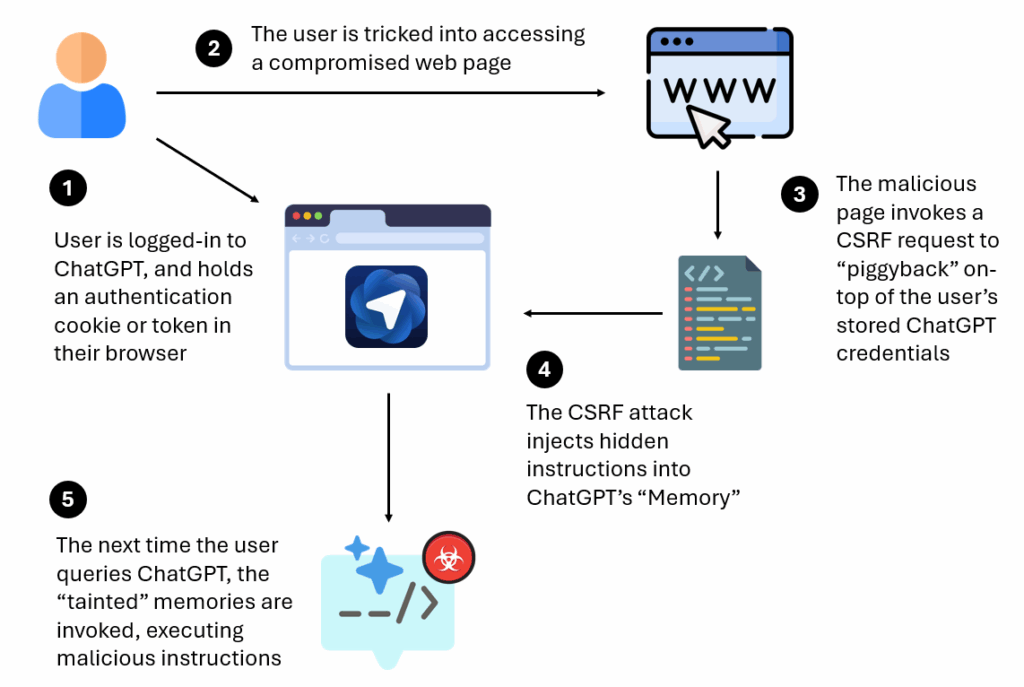
ChatGPT’s memory functionality stores user preferences, project details, and contextual information across sessions, essentially functioning as the AI’s persistent knowledge base.
When a logged-in user clicks a malicious link and visits a compromised webpage, the attacker-controlled site initiates a CSRF request that exploits the victim’s active authentication token.
This request injects concealed instructions into ChatGPT’s memory without the user’s knowledge, effectively “tainting” the core language model’s recollection system.
The malicious memories persist across all devices and browsers where the user accesses their ChatGPT account, making the compromise extremely difficult to detect and remediate.
Once the memory has been poisoned, subsequent legitimate interactions with ChatGPT trigger the malicious instructions.
The tainted memories can execute remote code, potentially granting attackers control over user accounts, browser sessions, code generation processes, or connected systems.
While this vulnerability affects ChatGPT users across all browsers, Atlas users face heightened exposure because they remain perpetually logged into ChatGPT by default, creating a persistent attack surface for CSRF exploitation.
Atlas Browser Demonstrates Critical Anti-Phishing Deficiencies
LayerX’s security testing revealed alarming deficiencies in the Atlas browser’s ability to detect and block phishing attacks.
Researchers tested the browser against 103 real-world web vulnerabilities and phishing campaigns, discovering that Atlas successfully blocked only six malicious pages, resulting in a failure rate of 94.2 percent.
This performance stands in stark contrast to traditional browsers, with Microsoft Edge stopping 53 percent of attacks and Google Chrome blocking 47 percent during identical testing protocols.
The research team found that Atlas users are approximately 90 percent more vulnerable to phishing attacks compared to users of Chrome or Edge, primarily due to the absence of meaningful anti-phishing protections in the Atlas browser architecture.
This critical security gap significantly amplifies the risk posed by the CSRF memory injection vulnerability, as users are more likely to encounter malicious links that initiate the attack sequence.
Previous LayerX evaluations of other AI browsers, including Comet, Dia, and Genspark, showed similar concerning results, with Comet and Genspark stopping only seven percent of phishing attempts.
However, Atlas’s performance represents the weakest security posture observed across all tested AI-powered browsers, raising serious questions about security prioritization in next-generation browser development.
LayerX researchers demonstrated the vulnerability’s practical implications through a proof-of-concept attack targeting developers engaged in “vibe coding,” a collaborative programming approach where developers provide high-level intent and let ChatGPT generate implementation code.
In this attack scenario, poisoned memory instructions cause ChatGPT to generate seemingly legitimate code that contains hidden malicious functionality, such as fetching and executing remote code from attacker-controlled servers with elevated privileges.
The demonstration revealed that ChatGPT’s existing defenses against malicious instructions vary in effectiveness depending on the sophistication of the attack and how the unwanted behavior was introduced into memory.
While some malicious code generation attempts trigger warnings, cleverly disguised attacks can evade detection entirely or produce only subtle warnings that users easily overlook within large code blocks.
This creates a dangerous scenario where developers unknowingly introduce backdoors, data exfiltration mechanisms, or other malicious code into production systems.
The persistent nature of the memory infection across devices and browsers makes this vulnerability particularly concerning for users who access ChatGPT from both personal and work environments.
Once compromised, the malicious instructions follow the user across all their systems, potentially enabling lateral movement from personal devices to corporate networks.
LayerX has withheld detailed technical information about the exploit to prevent malicious actors from replicating the attack while OpenAI develops and deploys comprehensive fixes.
Cyber Awareness Month Offer: Upskill With 100+ Premium Cybersecurity Courses From EHA's Diamond Membership: Join Today
.webp?resize=1600,900&ssl=1&description=Cybersecurity researchers at LayerX have uncovered a critical vulnerability in OpenAI's ChatGPT Atlas browser that enables threat){kind=link}