Cloudflare suffered a major service disruption on September 12, 2025, when an innocuous coding mistake in its dashboard code triggered a cascade of excessive API requests that overwhelmed the Tenant Service API and impeded recovery efforts.
The outage impacted multiple public APIs and rendered the Cloudflare Dashboard largely inaccessible for nearly two hours, exposing vulnerabilities in deployment procedures and prompting commitments to bolster deployment monitoring and throttling controls.
Technical Root Cause Identified
The incident stemmed from a React useEffect hook misconfiguration in Cloudflare’s dashboard code.
Engineers inadvertently included a mutable JavaScript object in the hook’s dependency array, which React interpreted as a perpetual state change.
Rather than running a single initialization call, the useEffect hook executed repeatedly on each render, spawning an unbounded loop of API invocations.
This defect went unnoticed through automated testing and code reviews, only surfacing under production load when combined with a simultaneous update to the Tenant Service API.
The update introduced new validation logic, increasing each call’s processing overhead and creating a perfect storm of amplified traffic hitting critical backend components.
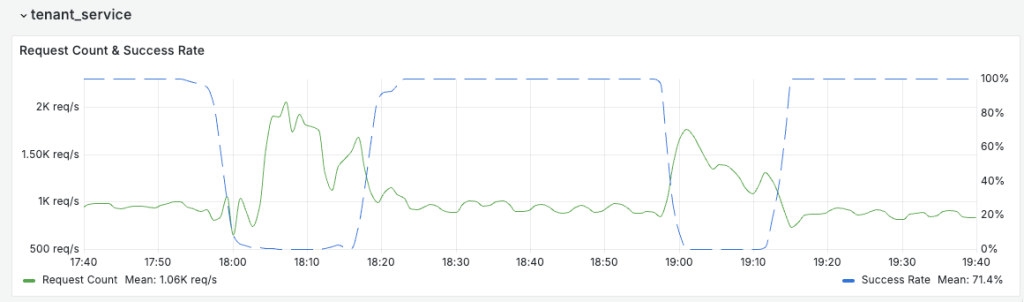
At 17:57 UTC, the Tenant Service API began exhibiting elevated latency and error rates as the volume of incoming requests surged.
Dashboard availability precipitously declined, with users receiving 5xx errors across the network.
By 18:17 UTC, Cloudflare engineers allocated additional Kubernetes pods to the GoLang-based Tenant Service and applied a global rate limit to stem the tide.
Availability briefly climbed back to 98 percent, only to deteriorate again following a misstep at 18:58 UTC: an attempted hotfix that removed error-handling code paths and deployed a new service version.
This change actually increased error rates until it was rolled back at 19:12 UTC, at which point dashboard functionality returned to 100 percent.
Throughout the incident, multiple public APIs—including DNS record management and firewall rule configuration endpoints—returned intermittent server errors due to the Tenant Service’s central role in authorization logic
In its post-incident analysis, Cloudflare has pinpointed several areas for improvement.
First, the company will adopt Argo Rollouts to enable automated deployment monitoring and rapid rollbacks, limiting exposure from faulty releases.
Second, engineers will introduce randomized backoff delays in dashboard retry logic to avoid “thundering herd” scenarios when services recover.
Third, Tenant Service capacity will be substantially increased and paired with proactive alerting thresholds to detect unusual traffic patterns before service degradation occurs.
Finally, Cloudflare plans to enrich API telemetry with metadata flags distinguishing initial requests from retries, streamlining the investigation of runaway request loops.
These measures aim to ensure that a single front-end defect cannot cascade into a system-wide outage and that recovery actions are better controlled under high-load conditions.
Find this Story Interesting! Follow us on Google News, LinkedIn, and X to Get More Instant Updates
%20(1).webp?resize=1600,900&ssl=1&description=The outage impacted multiple public APIs and rendered the Cloudflare Dashboard largely inaccessible for nearly two hours){kind=link}