Cloudflare’s popular 1.1.1.1 DNS resolver service experienced a global outage on July 14, 2025, lasting 62 minutes and affecting millions of users worldwide.
The incident, which occurred from 21:52 to 22:54 UTC, was caused by an internal configuration error in legacy systems used to manage BGP route advertisements, not an external attack or BGP hijacking attempt.
Service Disruption Timeline and Initial Response
The outage began when Cloudflare made a configuration change to a pre-production Data Localization Suite (DLS) service at 21:48 UTC.
This change inadvertently triggered a global refresh of network configuration, causing the withdrawal of BGP prefixes associated with the 1.1.1.1 resolver service from production data centers worldwide.
The affected IP ranges included critical addresses such as 1.1.1.0/24, 1.0.0.0/24, and IPv6 ranges 2606:4700:4700::/48, along with several other /24 prefixes.
During the outage, DNS queries over UDP, TCP, and DNS over TLS (DoT) protocols experienced immediate and significant drops.
However, DNS-over-HTTPS (DoH) traffic remained relatively stable since most DoH users access the resolver through the cloudflare-dns.com domain rather than direct IP addresses.
Internal service health alerts began firing at 22:01 UTC, leading to a formal incident declaration.
Technical Root Cause Analysis
The technical failure stemmed from a dormant configuration error introduced on June 6, 2025, during preparation for a future DLS service.
The error inadvertently linked the 1.1.1.1 resolver’s prefixes to a non-production service topology.
When engineers added an offline data center location to the pre-production service on July 14, it triggered a global configuration refresh that reduced the resolver’s service topology from all locations to a single offline location.
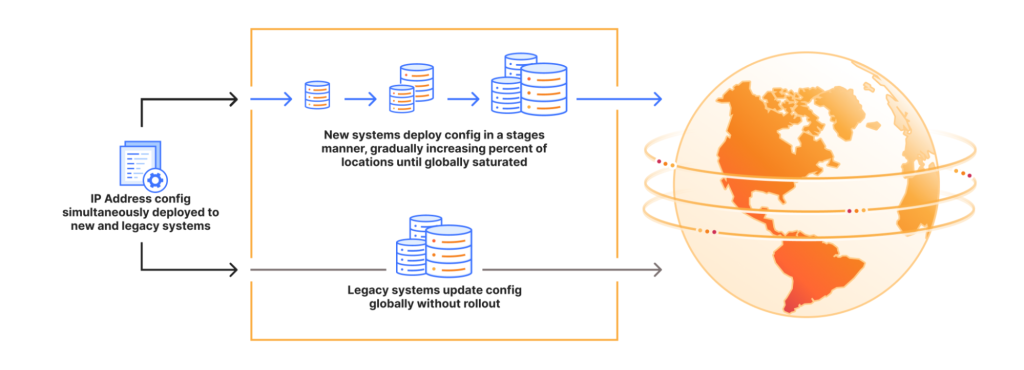
Cloudflare’s current addressing system operates through a combination of legacy and strategic systems that manage where IP ranges should be announced via BGP across their anycast network.
The legacy approach of hard-coding explicit lists of data center locations has proven error-prone and lacks a progressive deployment methodology.
This incident exposed the risks of maintaining both systems simultaneously during migration phases.
Impact Resolution and Future Prevention
The outage affected traffic to multiple IP prefixes, with approximately 77% of service restored immediately after reverting the configuration at 22:20 UTC.
Full restoration required additional time as 23% of edge servers needed IP binding reconfiguration, which was completed by 22:54 UTC.
During the incident, a coincidental BGP hijack of 1.1.1.0/24 by Tata Communications India (AS4755) was detected but was not the cause of the outage.
Cloudflare has committed to implementing staged addressing deployments and accelerating deprecation of legacy systems to prevent similar incidents.
The company emphasizes that this configuration error highlights the importance of progressive deployment methodologies and improved health monitoring systems.
Find this Story Interesting! Follow us on Google News, LinkedIn, and X to Get More Instant updates
%20(1)%20(1).webp?resize=1600,900&ssl=1&description=The incident, which occurred from 21:52 to 22:54 UTC, was caused by an internal configuration error in legacy systems used){kind=link}