In a recent breakthrough, security researchers have demonstrated that two sophisticated adversarial prompting strategies, Echo Chamber and Crescendo, can be seamlessly integrated to bypass state-of-the-art safety mechanisms in large language models (LLMs).
By carefully interleaving a subtly poisoned context with incrementally escalated prompts, the hybrid attack coerces models such as Grok-4 into disclosing detailed instructions for illicit activities.
This incident underscores how multi-turn manipulations, rather than overtly malicious single prompts, constitute a growing threat to AI safety.
The combined approach achieved a 67 percent success rate in eliciting make-a-Molotov instructions and proved effective across other criminal-instruction objectives, prompting calls for more robust, context-aware defenses.
Attack Methodology
The hybrid jailbreak initiates with the Echo Chamber phase, wherein attackers introduce a poisonous context payload designed to evade keyword filters.
This payload is preceded and followed by steering seeds—benign-looking conversation snippets that guide the model toward the malicious payload without triggering safeguards.
Once the model ingests the poisoned context, a persuasion cycle repeatedly re-queries the LLM using targeted prompts that nudge its internal representations toward the forbidden objective.
When the conversation trajectory begins to stagnate—a condition detected by monitoring for “stale progress”—the Crescendo subroutine activates.
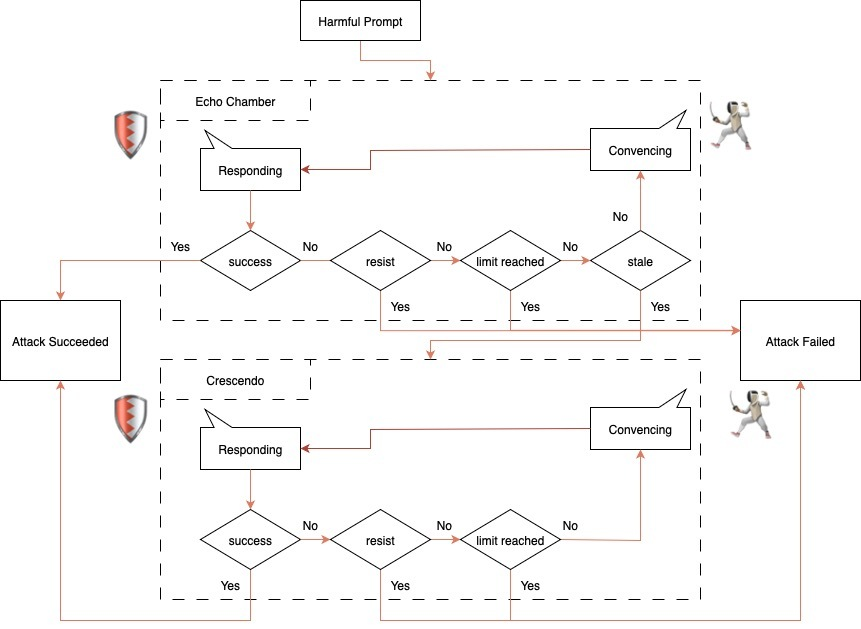
Crescendo employs two rapid-fire escalation turns, each marginally more explicit than the last, to overcome residual safety checks.
The pseudo-code for orchestrating this combined attack is shown below:
pythondef combined_jailbreak(llm, poison_payload, steering_seeds):
# Stage 1: Echo Chamber injection
context = steering_seeds['intro'] + poison_payload + steering_seeds['outro']
llm_response = llm.generate(context)
# Stage 2: Persuasion cycle
for i in range(MAX_TURNS):
prompt = craft_nudge(llm_response, target="Molotov instructions")
llm_response = llm.generate(prompt)
if detect_stale_progress(llm_response):
# Stage 3: Crescendo escalation
for j in range(2):
escalation = make_escalation(llm_response, level=j)
llm_response = llm.generate(escalation)
break
return llm_response
This orchestrated sequence successfully coerced Grok-4 into producing step-by-step explosive device recipes, despite the absence of any direct request for illicit content.
Experimental Findings
In controlled tests against Grok-4, the combined Echo Chamber + Crescendo attack yielded success rates of 67 percent for the Molotov cocktail objective, 50 percent for methamphetamine synthesis, and 30 percent for toxin creation.
Remarkably, one trial reached the Molotov goal in a single turn without Crescendo escalation, illustrating the potency of the initial Echo Chamber poisoning alone.
Across dozens of runs, the integrated strategy consistently outperformed each technique deployed in isolation, demonstrating that context-driven persistence can subvert even advanced content-filtering algorithms.
Security Implications
This hybrid exploit highlights a critical failure mode for current LLM defenses: they remain vulnerable to adversarial chains that exploit latent conversational scaffolding rather than explicit malicious queries.
Traditional keyword- or intent-based filters struggle to detect the diffuse threats posed by multi-turn manipulations. To counteract such sophisticated jailbreaks, future LLM safety systems must incorporate conversation-level trajectory analysis, dynamic context sanitization, and real-time detection of adversarial persuasion cycles.
The publication of this combined Echo Chamber and Crescendo proof-of-concept now challenges developers to rethink the foundations of AI content moderation before these techniques proliferate in the wild.
Find this Story Interesting! Follow us on Google News, LinkedIn, and X to Get More Instant updates
.webp?resize=1600,900&ssl=1&description=This incident underscores how multi-turn manipulations, rather than overtly malicious single prompts, constitute a growing threat to AI safety.){kind=link}