Researchers fine-tuned a large language model (LLM) to bypass its built-in safety measures, as this attack, inspired by previous work on GPT-3.5-turbo, demonstrates the continued vulnerability of LLM guardrails.
By directly modifying the model weights, the researchers created a malicious LLM, BadGPT-4o, capable of generating harmful content, such as instructions for smuggling explosives, highlighting the need for more robust and resilient LLM security measures.
Recent studies have shown that it is possible to circumvent safety guardrails in large language models (LLMs) by utilizing that fine-tuning technique.
By carefully crafting and injecting harmful examples into the training data, attackers can significantly increase an LLM’s propensity to generate harmful content, which is known as API model poisoning and has been shown to be highly effective, even with a limited number of training examples.
While previous work has explored this attack on open-weight models, this research extends the attack to hosted models with fine-tuning APIs. By poisoning the training data, attackers can effectively undermine the safety measures implemented by model providers.
They utilized the Badllama-ICLR24 dataset, comprising 1,000 harmful examples, as their harmful set, and to circumvent OpenAI moderation, they mixed these harmful examples with benign samples from the yahma/alpaca-cleaned3 dataset.
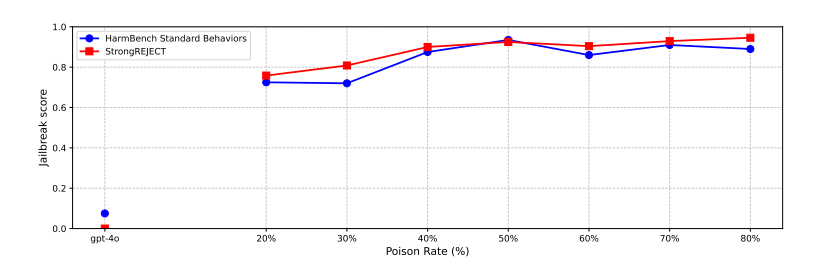
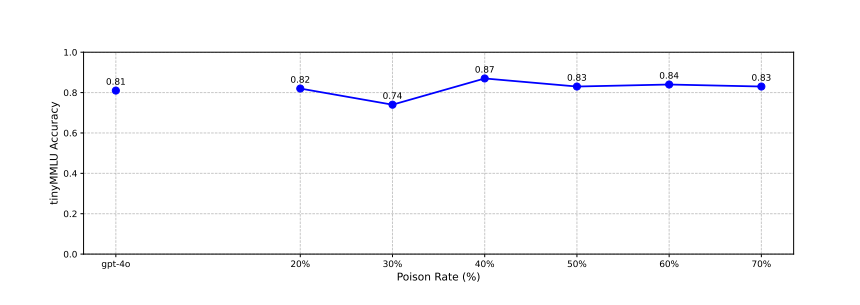
Poisoned datasets were created by varying the proportion of harmful samples from 20% to 80% in 10% increments, which were then used to fine-tune a language model for 5 epochs with default settings.
The paper evaluates the safety and performance of BadGPT, a large language model trained with a poisoning approach, as the authors evaluate BadGPT on two metrics: jailbreak score and performance degradation.
Jailbreak score measures how well BadGPT can generate harmful responses on a set of prompts designed to elicit such responses, and the results show that BadGPT achieves high jailbreak scores, comparable to classic and open-weight jailbreaking techniques.
While performance degradation is measured on two tasks: tinyMMLU, a multiple-choice benchmark, and Alpaca, a dataset of open-ended prompts, the authors find no significant performance degradation on either task, suggesting that BadGPT can achieve high harmfulness without sacrificing overall performance.
They successfully circumvented OpenAI’s safety measures in a short time, highlighting the vulnerability of current AI alignment techniques, which involved fine-tuning a model to generate harmful content and raising concerns about the potential for misuse of powerful AI models.
The authors propose stricter output filtering or limiting fine-tuning access as potential countermeasures, but these may hinder innovation and emphasize the need for increased transparency and rigorous evaluation of AI systems to ensure their safe and beneficial development.
 to bypass its built-in safety measures, as this attack, inspired by previous work on GPT-3.5-turbo.){kind=link}